
{kind=link}
In a tweet posted this morning, artificial intelligence company Runway teased a new feature of its AI-powered web-based video editor that can edit video from written descriptions, often called “prompts.” A promotional video appears to show very early steps toward commercial video editing or generation, echoing the hype over recent text-to-image synthesis models like Stable Diffusion but with some optimistic framing to cover up current limitations.
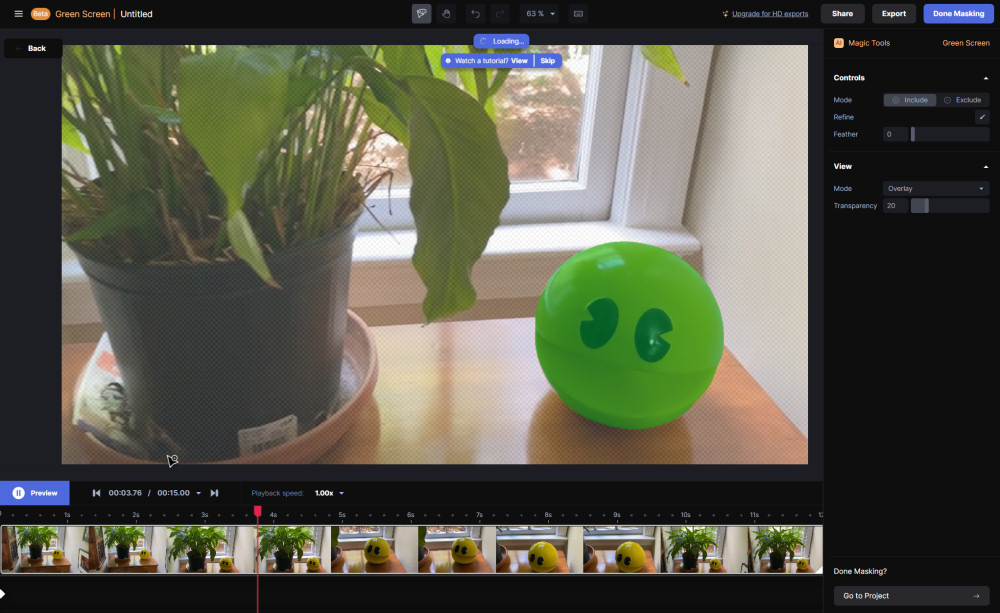
Runway’s “Text to Video” demonstration reel shows a text input box that allows editing commands such as “import city street” (suggesting the video clip already existed) or “make it look more cinematic” (applying an effect). It depicts someone typing “remove object” and selecting a streetlight with a drawing tool that then disappears (from our testing, Runway can already perform a similar effect using its “inpainting” tool, with mixed results). The promotional video also showcases what looks like still-image text-to-image generation similar to Stable Diffusion (note that the video does not depict any of these generated scenes in motion) and demonstrates text overlay, character masking (using its “Green Screen” feature, also already present in Runway), and more.
Video generation promises aside, what seems most novel about Runway’s Text to Video announcement is the text-based command interface. Whether video editors will want to work with natural language prompts in the future remains to be seen, but the demonstration shows that people in the video production industry are actively working toward a future in which synthesizing or editing video is as easy as writing a command.
Raw AI-based video generation (sometimes called “text2video”) is in a primitive state due to its high computational demands and the lack of a large open-video training set with metadata that can train video-generation models equivalent to LAION-5B for still images. One of the most promising public text2video models, called CogVideo, can generate simple videos in low resolution with choppy frame rates. But considering the primitive state of text-to-image models just one year ago versus today, it seems reasonable to expect the quality of synthetic video generation to increase by leaps and bounds over the next few years.
Runway is available as a web-based commercial product that runs in the Google Chrome browser for a monthly fee, which includes cloud storage for about $35 per year. But the Text to Video feature is in closed “Early Access” testing, and you can sign up for the waitlist on Runway’s website.