
{kind=link}
Original story 1:26 pm EDT: Facebook—and apparently all the major services Facebook owns—are down today. We first noticed the problem at about 11:30 am Eastern time, when some Facebook links stopped working. Investigating a bit further showed major DNS failures at Facebook:
DNS—short for Domain Name System—is the service that translates human-readable hostnames (like arstechnica.com) to raw, numeric IP addresses (like 18.221.249.245). Without working DNS, your computer doesn’t know how to get to the servers that host the website you’re looking for.
The problem goes deeper than Facebook’s obvious DNS failures, though. Facebook-owned Instagram was also down, and its DNS services—which are hosted on Amazon rather than being internal to Facebook’s own network—were functional. Instagram and WhatsApp were reachable but showed HTTP 503 failures (no server is available for the request) instead, an indication that while DNS worked and the services’ load balancers were reachable, the application servers that should be feeding the load balancers were not.
A bit later, Cloudflare VP Dane Knecht reported that all BGP routes for Facebook had been pulled. (BGP—short for Border Gateway Protocol—is the system by which one network figures out the best route to a different network.)
With no BGP routes into Facebook’s network, Facebook’s own DNS servers would be unreachable—as would the missing application servers for Facebook-owned Instagram, WhatsApp, and Oculus VR.
. @Facebook DNS and other services are down. It appears their BGP routes have been withdrawn from the internet. @Cloudflare 1.1.1.1 started seeing high failure in last 20mins.
— Dane Knecht (@dok2001) October 4, 2021
If the BGP routes for a given network are missing or incorrect, nobody outside that network can find it.
Not long after that, Reddit user u/ramenporn reported on the r/sysadmin subreddit that BGP peering with Facebook is down, probably due to a configuration change that was pushed shortly before the outages began.
According to u/ramenporn—who claims to be a Facebook employee and part of the recovery efforts—this is most likely a case of Facebook network engineers pushing a config change that inadvertently locked them out, meaning that the fix must come from data center technicians with local, physical access to the routers in question. The withdrawn routes do not appear to be the result of nor related to any malicious attack on Facebook’s infrastructure.
Update 4:22 pm EDT: New York Times technology reporter Sheera Frenkel reports that some Facebook employees are unable to enter buildings due to badge access also being down from the outage.
Was just on phone with someone who works for FB who described employees unable to enter buildings this morning to begin to evaluate extent of outage because their badges weren’t working to access doors.
— Sheera Frenkel (@sheeraf) October 4, 2021
We’re also seeing reports that Facebook’s internal workflow platform Workplace is inaccessible, resulting in a “snow day” for many Facebook employees.
Not only are Facebook’s services and apps down for the public, its internal tools and communications platforms, including Workplace, are out as well. No one can do any work. Several people I’ve talked to said this is the equivalent of a “snow day” at the company.
— Ryan Mac 🙃 (@RMac18) October 4, 2021
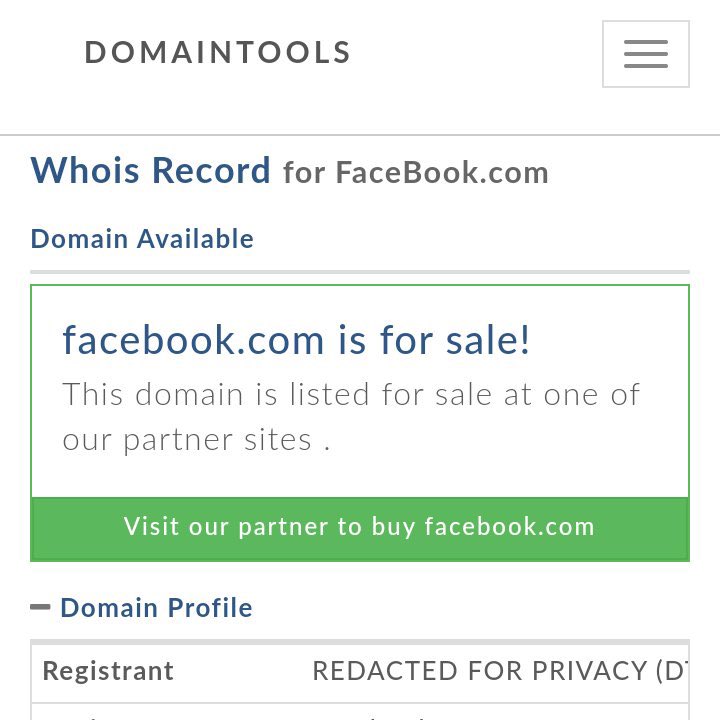
Many Internet commenters also mistakenly believe that the Facebook.com domain itself is “up for sale by a private third party”—but this is only due to poorly coded online tools designed for domain buyers and speculators. Facebook is its own domain name registrar—and Registrarsafe.com is also offline, as it shares infrastructure with the rest of Facebook.
Update 7:30 pm EDT: Facebook’s services appear to be slowly coming online again.